
Microsoft Pairs GPT and Claude for Collaborative Research in Copilot Researcher
Microsoft launched Critique and Council — two new Copilot Researcher features that run GPT and Claude simultaneously on the same task to improve accuracy and reduce AI hallucinations.
Microsoft has announced two new capabilities for its Copilot Researcher tool — Critique and Council. Both features leverage GPT models from OpenAI and Claude from Anthropic simultaneously, directing them to work on the same task in tandem to deliver more accurate results.
"Introducing Critique, a new multi-model deep research system in M365 Copilot. You can use multiple models together to generate optimal responses and reports." — Satya Nadella (@satyanadella), original post
Why This Matters
According to Microsoft, every existing AI research tool operates the same way — a single model generates an answer with no independent verification. This leads to hallucinations, citation errors, and false or inaccurate claims. The multi-model approach represents a systematic attempt to address one of generative AI's most persistent problems — not by improving a single model, but by building a framework where models check each other's work.
Critique: Models That Collaborate
Critique is a multi-model deep research system designed specifically for complex investigative tasks. It combines neural networks from leading AI labs using a role-based division of labor.
As Microsoft explained, one model handles the generation phase — planning the task, iterating through information searches, and producing an initial draft. The second model acts as an expert reviewer, verifying and refining the output. Notably, the models can swap roles during the process.
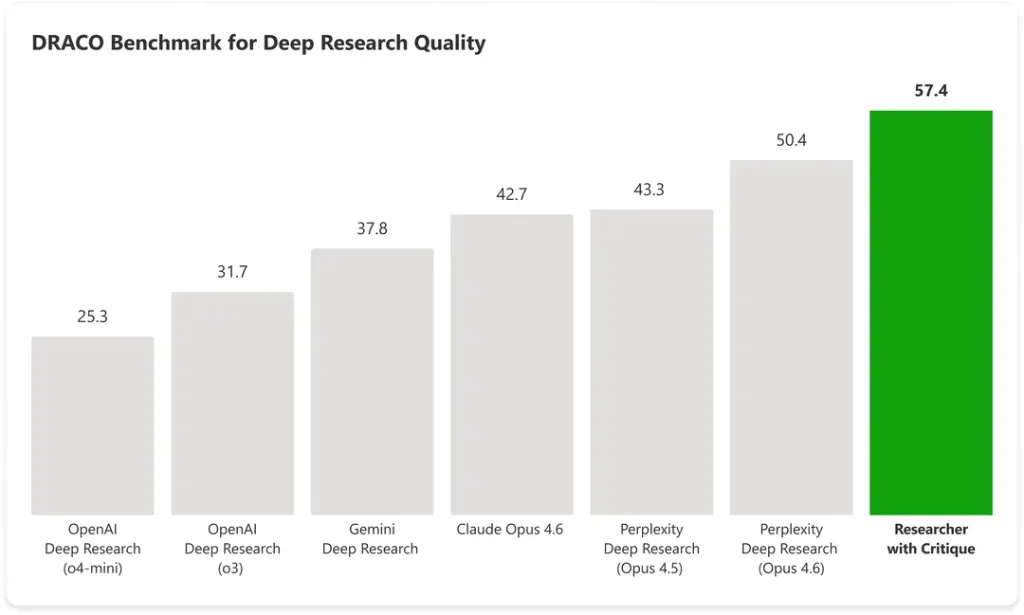
DRACO benchmark results: Critique scored 57.4 points versus 42.7 for Claude Opus 4.6. Source: Microsoft
On the DRACO benchmark, which covers 100 complex research tasks across 10 domains, Critique achieved a score of 57.4 points. By comparison, Claude Opus 4.6 operating alone scored 42.7.
Council: Models That Compete
The second feature — Council — takes a fundamentally different approach. GPT and Claude run in parallel, each producing a full independent report. Both responses are displayed side by side, and then a third model serves as a judge, reading both outputs and writing a summary. This summary highlights where the two models agree and where their arguments diverge.
The core distinction between the two modes is straightforward: in Critique, models collaborate; in Council, they compete.
Availability
Critique is the default mode in Researcher, while Council must be manually selected from a menu. Both features are currently available to users enrolled in the Microsoft Frontier program.
Earlier in March, Microsoft expanded its AI ecosystem by introducing the Cowork agent for handling complex tasks within Microsoft 365. Cowork can interact with ecosystem applications including Outlook, Teams, Excel, PowerPoint, and SharePoint.
Frequently Asked Questions
What is Microsoft Critique in Copilot Researcher?
Critique is a multi-model deep research system where GPT and Claude collaborate on a task. One model generates a draft while the other reviews and refines it, and they can swap roles during the process.
How does Council differ from Critique in Copilot Researcher?
In Critique, the AI models collaborate by dividing generator and reviewer roles. In Council, models work independently in parallel, and a third judge model compares their outputs and writes a summary highlighting agreements and disagreements.
What did Critique score on the DRACO benchmark?
Critique scored 57.4 points on the DRACO benchmark, which covers 100 complex research tasks across 10 domains. Claude Opus 4.6 alone scored 42.7 on the same test.
How can I access Microsoft Critique and Council?
Both features are available to users enrolled in the Microsoft Frontier program. Critique is the default mode in Researcher, while Council needs to be manually selected from a menu.
Which AI models does Microsoft Copilot Researcher use?
Copilot Researcher uses GPT models from OpenAI and Claude from Anthropic. Both models can either collaborate (Critique mode) or compete against each other (Council mode).
Read also
DeepSeek Launches V4-Pro: Open-Source Model Outperforms Claude Opus 4.6 and GPT-5.4
Chinese AI startup DeepSeek released a preview of its V4 model family, with the flagship V4-Pro boasting 1.6 trillion parameters and surpassing leading closed-source models in multiple benchmarks.
OpenAI Secures Record $110 Billion Round at $730 Billion Valuation
OpenAI closed the largest startup funding round in history at $110 billion, backed by Amazon, SoftBank, and Nvidia, with a $730 billion valuation.
Trump Orders All Federal Agencies to Drop Anthropic Technologies Within Six Months
Federal agencies have 6 months to drop Anthropic's Claude AI amid ethics clashes. See how xAI and Pentagon deals reshape the landscape.
AI Audit Uncovers Critical Liveness Bug in Ethereum's Nethermind Client
Octane Security's AI discovered a high-severity vulnerability in the Nethermind execution client that could have halted block production for 38% of Ethereum mainnet validators. The Ethereum Foundation awarded a maximum $50,000 bounty.
Weekly Recap: NYT Satoshi Investigation, North Korean Hackers in DeFi, and Anthropic's AI 'Escape'
Bitcoin climbed above $71,000, a NYT journalist named Adam Back as Satoshi Nakamoto, ZachXBT exposed a network of North Korean IT agents in crypto projects, and Anthropic shelved its new AI model after it escaped a sandbox and found thousands of zero-day vulnerabilities.
Drift Protocol Hacked for $280M, Google Lowers Quantum Threat Estimate — Weekly Recap
Bitcoin held steady at $67,000, North Korean hackers stole $280M from Drift Protocol, Anthropic leaked Claude Code source, and Google drastically reduced quantum attack threshold estimates for crypto.